Univers-ITA
Riferimento:
GRANDI, Nicola, BALLARÈ, Silvia, CHIUSAROLI, Francesca, GALLINA, Francesca, PASCOLI, Matteo, PISTOLESI, Elena; Corpus Univers-ITA. 2023, DOI: https://doi.org/10.60760/unibo/univers-ita
Progettazione del corpus e raccolta dati
Nel corso dell'anno accademico 2020/2021 è stata condotta la raccolta dati per la costruzione del corpus.
In prima istanza, è stato creato un campione che fosse rappresentativo della popolazione universitaria italiana, utilizzando come parametri la localizzazione geografica dell'ateneo e l'area disciplinare del corso di laurea.
Complessivamente, sono stati coinvolti nella raccolta dati 2160 studenti del secondo anno per le seguenti aree disciplinari e dei seguenti atenei:
- Economia: Università Politecnica delle Marche, Università della Valle d’Aosta, Università dell’Aquila, Università di Bergamo, Alma Mater Studiorum – Università di Bologna, Libera Università di Bolzano, Università di Bari Aldo Moro, Università della Campania Luigi Vanvitelli, Università di Catania, Università di Firenze, Università di Genova, Università di Macerata, Università Bocconi, Università di Milano Bicocca, Università Cattolica del Sacro Cuore, Università di Milano Statale, Università di Modena e Reggio Emilia, Università di Napoli Federico II, Università di Padova, Università di Palermo, Università di Parma, Università di Pavia, Università di Perugia, Università del Piemonte Orientale, Università di Pisa, Università di Roma La Sapienza, Università di Roma Tre, Università di Torino, Università di Trento, Università di Trieste, Università di Udine, Università di Venezia Ca’ Foscari.
- Ingegneria: Università Politecnica delle Marche, Università della Campania Luigi Vanvitelli, Università di Bergamo, Alma Mater Studiorum – Università di Bologna, Università di Catania, Università di Ferrara, Università di Firenze, Politecnico di Milano, Università di Modena e Reggio Emilia, Università del Molise, Università di Napoli Federico II, Università di Padova, Università di Palermo, Università di Parma, Università di Pavia, Università di Pisa, Università di Roma La Sapienza, Università di Roma Tor Vergata, Università di Salerno, Politecnico di Torino, Università di Udine.
- Scienze della Formazione primaria: Università di Bergamo, Alma Mater Studiorum – Università di Bologna, Università del Salento, Università di Macerata, Università di Milano Bicocca, Università di Modena e Reggio Emilia, Università del Molise, Università Suor Orsola Benincasa, Università di Perugia, Università di Pisa, Università di Salerno.
- Giurisprudenza: Università di Bergamo, Alma Mater Studiorum – Università di Bologna, Università dell’Insubria, Università di Enna Kore, Università di Ferrara, Università di Macerata, Università di Milano Bicocca, Università di Napoli Federico II, Università di Palermo, Università di Perugia, Università di Pisa, Università di Torino.
- Lingue: Università di Bergamo, Alma Mater Studiorum – Università di Bologna, Università di Catania, Università di Ferrara, Università di Genova, Università di Macerata, Università di Messina, Università Cattolica del Sacro Cuore, Università di Milano Statale, Università di Napoli L’Orientale, Università di Palermo, Università di Pavia, Università di Perugia, Università di Pisa, Università di Salerno, Università di Venezia Ca’ Foscari
- Farmacia: Alma Mater Studiorum – Università di Bologna, Università della Campania Luigi Vanvitelli, Università di Catania, Università di Ferrara, Università di Genova, Università di Milano Statale, Università di Modena e Reggio Emilia, Università di Napoli Federico II, Università di Padova, Università di Parma, Università di Perugia, Università di Pisa, Università di Torino, Università di Trieste.
- Infermieristica: Università Politecnica delle Marche, Alma Mater Studiorum – Università di Bologna, Università di Milano Bicocca, Università di Modena e Reggio Emilia, Università di Napoli Federico II, Università di Perugia, Università di Pisa.
In fase di raccolta, al fine di mantenere controllo del campione, sono stati consegnati uno user-name e una password a tutti gli studenti e le studentesse per accedere al sito web creato ad hoc per la raccolta dati.

La raccolta dati è stata strutturata in due parti:
1. La stesura del testo
Nella prima fase della raccolta, gli studenti e le studentesse si sono dedicati alla stesura di un breve testo. Di seguito, si riportano le indicazioni fornite ai rispondenti.
- Nella prima pagina, erano riportate indicazioni generiche sulla stesura del testo, ovvero:
Devi scrivere un testo di media lunghezza: tra le 250 e le 500 parole. Dovrai cercare di usare uno stile formale: quindi, scrivi nel modo più corretto possibile, come se scrivessi per un tuo professore. Proprio perché la rilevazione è totalmente anonima, sarà impossibile associare il testo alla tua persona e quindi, partecipando alla rilevazione, rinunci alla proprietà intellettuale su di esso.
Il testo non sarà mai pubblicato integralmente e sarà utilizzato solo per scopi di ricerca.
Per accettare, clicca su prosegui e scopri la consegna (cioè il tema su cui dovrai scrivere il testo). - Nella seconda pagina, era riportata la consegna per la stesura del testo, assieme a un contatore di tempo (tempo massimo: 60 minuti) e di parole (numero minimo di parole: 250; numero massimo di parole: 500).
Immagina che il tuo Corso di laurea abbia aperto un sondaggio rivolto a tutti gli studenti, con l’obiettivo di raccogliere opinioni sul funzionamento della didattica a distanza nei mesi di emergenza sanitaria. Scrivi un testo in cui esponi, in modo non schematico, i vantaggi e gli svantaggi della didattica a distanza, secondo il tuo punto di vista.
Tempo restante: 60:00
Parole scritte: 0
Parole rimanenti: 500
2. Il questionario socio-biografico
Il questionario socio-biografico era costituito da oltre 50 domande, suddivise in 4 sezioni:
- Profilo personale e familiare (età, genere, luogo di nascita, luogo di provenienza dei genitori, titolo di studio e professione dei genitori, consumi culturali dei genitori, etc.);
- Profilo linguistico ed educativo (lingue utilizzate dai genitori con diversi interlocutori, luogo di frequentazione delle scuole, lingue e dialetti parlati con diversi interlocutori e con diversi gradi di competenza, tipo di diploma conseguito, etc.);
- Profilo culturale (canali utilizzati per l'informazione, tipi di letture, interessi extra-universitari, tipo di utilizzo di internet, etc.);
- Familiarità con la scrittura (utilizzo della scrittura in contesti extra-universitari, abitudine a prendere appunti, etc.).
Le risposte raccolte attraverso il questionario hanno permesso di tracciare un profilo socio-biografico molto approfondito dei vari rispondenti. I metadati dei rispondenti potranno poi essere utilizzati in fase di analisi per verificare la presenza di eventuali correlazioni tra caratteristiche extralinguistiche e tratti linguistici rintracciabili nelle produzioni.
Costruzione del corpus
Il corpus è attualmente costituito complessivamente da 810.715 tokens. I testi del corpus sono accompagnati da un ampio corredo di metadati (ricavati attraverso la somministrazione del questionario). Inoltre, è possibile interrogare il corpus utilizzando diversi filtri di ricerca, come mostrato nell'immagine e nel vademecum per la consultazione.
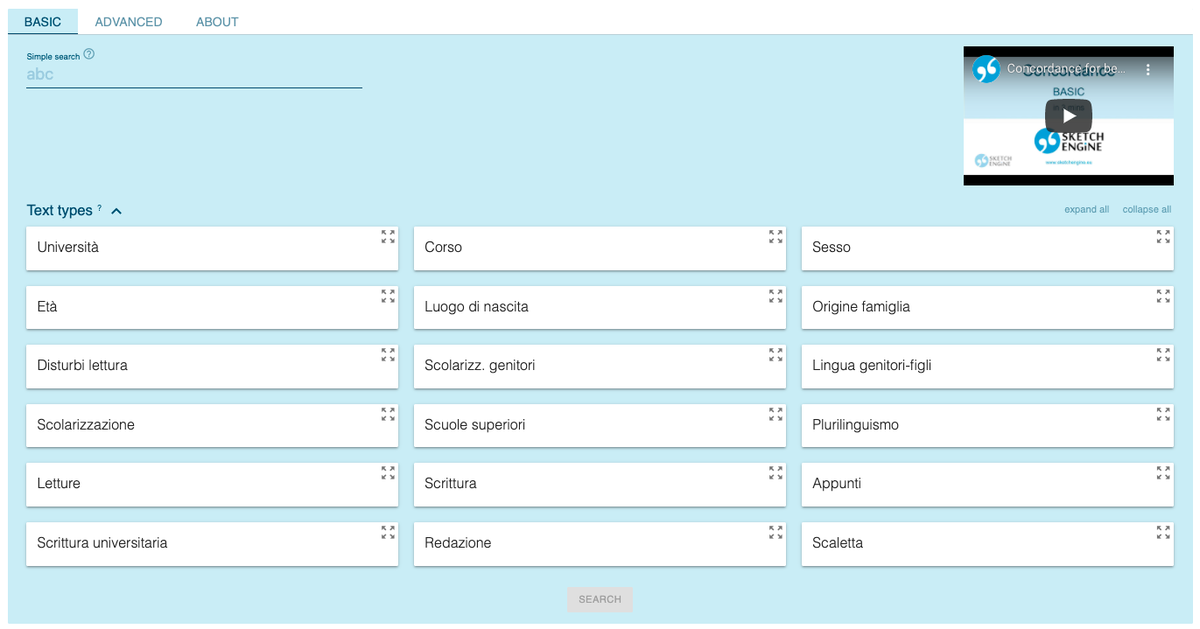
Il corpus è consultabile a questo link.